Entwickelt werden soll ein Modul, das sich mit der Verarbeitung gesprochener Sprache im Rechner beschäftigt. Das Lernziel besteht darin, den Studierenden die Aspekte der Verarbeitung gesprochener Sprache näherzubringen, die für die Entwicklung von Systemen der Sprachtechnologie im Bereich gesprochener Sprache wesentlich sind, also mit dem Bereich, der als Mensch-Maschine-Kommunikation mit gesprochener Sprache oder etwas vereinfachend als Akustische Mensch-Maschine-Kommunikation bezeichnet wird.
Grundlage dieses Moduls sind drei zweistündige Vorlesungen, die an der Universität Bonn im Fach Kommunikationsforschung und Phonetik im Rahmen des Magisterstudiengangs an der
Philosophischen Fakultät gehalten werden: Systeme der akustischen Mensch-Maschine-Kommunikation 1, 2 sowie die vorgeschaltete Vorlesung Grundlagen der Sprachsignalverarbeitung. In das Teilmodul Linguistische Aspekte gehen Materialien aus einem Seminar zur Fokusrealisierung und -interpretation ein, das im Sommersemester 1998 als gemeinsames Seminar der beiden Schwerpunkte Phonetik und Computerlinguistik im Fach Kommunikationsforschung und Phonetik stattfand.
Für zwei der drei Vorlesungen existieren ein ausführliches Skriptum sowie eine Foliendokumentation, die als PDF-Dateien im Internet abgelegt sind; für die dritte Vorlesung sind Skriptum und Foliendokumentation derzeit in Bearbeitung.
In immer stärkerem Maß ist in den Bereichen der Sprachtechnologie interdisziplinäres Arbeiten notwendig geworden. Dies betrifft insbesondere Anwendungen wie Sprachverstehenssysteme, Dialogsysteme oder textgesteuerte Sprachsynthesesysteme. Derartige Systeme verarbeiten
gesprochene Sprache auf allen Ebenen und enthalten damit einerseits Module, die das akustische Sprachsignal direkt verarbeiten, als auch Module, die die höheren Ebenen (Syntax, Semantik, Pragmatik usw.) im Rechner modellieren und damit traditionell der Computerlinguistik zuzuordnen sind. Wissenschaftler, die solche Systeme entwickeln, müssen sich daher auf beiden Gebieten bewegen können. In den Sprachwissenschaften im weiteren Sinne beschäftigt sich die
Phonetik mit der gesprochenen Sprache. Nicht von ungefähr ist es darum auch ein Lehrstuhl für
Phonetik, der in Bonn diesen Bereich abdeckt. Algorithmen und Module zur Verarbeitung gesprochener Sprache wurden (und werden) aber in der Regel nicht von Phonetikern, sondern von
Ingenieuren der Informationstechnik sowie von Informatikern entwickelt und implementiert.
Das macht die Verständigung zwischen der Computerlinguistik und den Disziplinen, die sich mit
der Verarbeitung gesprochener Sprache im Rechner beschäftigen, nicht gerade einfacher. Groß
projekte wie das vom BMBF geförderte Projekt Verbmobil haben sich mit diesem Problem auseinandersetzen müssen, aber dann auch Wege zu seiner Lösung und zum gegenseitigen Verständnis der Disziplinen gezeigt. An einigen Universitäten (z.B. Saarbrücken oder Stuttgart) sind
in den letzten 15 Jahren integrierte Diplomstudiengänge entstanden, in denen die Verarbeitung
geschriebener und gesprochener Sprache nebeneinander gelehrt wird. Im Fach Kommunikationsforschung und Phonetik der Universität Bonn ist ein solches Modell im Rahmen eines Magisterstudiengangs etabliert.
Die Gegenstände der Module überdecken sich in hohem Maß mit den Forschungsschwerpunkten des Instituts. Diese liegen u.a. auf: Sprachsynthese, Prosodie, formale Semantik, Untersuchung von Korpora. Zusammen mit drei anderen Partnern wurde am IKP das Sprachsynthesemodul für das Projekt Verbmobil entwickelt.
Das Bonner Studienfach Kommunikationsforschung und Phonetik
Das Bonner Fach Kommunikationsforschung und Phonetik besteht aus den beiden Schwerpunkten Phonetik/Akustische Kommunikation sowie Computerlinguistik. Hauptfachstudierende wählen spätestens im 2. Semester einen der beiden Schwerpunkte und studieren diesen im von den Studien- und Prüfungsordnungen vorgeschriebenen Umfang. Im Grundstudium sind für alle Studierenden auch einige Grundlagenveranstaltungen aus dem jeweils anderen Schwerpunkt verpflichtend. Seit 1997 besteht die Möglichkeit, das Fach als Hauptfach mit sich selbst als Nebenfach zu kombinieren; Studierende, die diese Option wählen, studieren beide Schwerpunkte in vollem Umfang und schreiben dann ihre Abschlussarbeit in einem der Schwerpunkte. Die drei obengenannten Lehrveranstaltungen sind verpflichtend für Kombinierer und Hauptfachstudierende des Schwerpunkts Phonetik/Akustische Kommunikation; für alle anderen Studierenden des Faches sind sie als Wahlpflichtveranstaltungen zugelassen.
Lehre zur akustischen Mensch-Maschine-Kommunikation
Wesentlicher Inhalt der beiden Vorlesungen Systeme der akustischen Mensch-Maschine-Kommunikation 1, 2, die als Grundlage für das zu erstellende Lehrmodul dienen und nachfolgend im Detail beschrieben sind, ist die Verarbeitung gesprochener Sprache im Rechner und mit rechnergestützten Methoden. Dieser Bereich gliedert sich traditionell in die beiden Aufgaben Spracheingabe und Sprachausgabe, die in modernen Anwendungen, wie Auskunfts- oder Dialogsysteme, in einem System gemeinsam vorkommen.
Schwerpunkt des Teilbereichs Spracheingabe ist die Spracherkennung. Hier werden zunächst die klassischen Mustererkennungsverfahren im Überblick vorgestellt, bevor dann mit den Hidden-Markov-Modellen die heute gängige Technik genauer behandelt wird. Nach einer kurzen Diskussion des Problems der Einzelworterkennung liegt der Schwerpunkt auf der Erkennung kontinuierlich gesprochener Sprache. An Anwendungen werden reine Spracherkennungssysteme (Diktiersysteme) und Sprachverstehenssysteme vorgestellt.
Bei der Sprachausgabe steht naturgemäß die textgesteuerte Sprachsynthese im Vordergrund; hier werden vor allem die heutigen Methoden konkatenativer und korpusbasierter Synthese eingehend behandelt. Dies schließt die zugehörigen Möglichkeiten der prosodischen Signalmanipulation unter Beibehaltung der spektralen Eigenschaften (z.B. PSOLA) mit ein. Der Schwerpunkt beider Lehrveranstaltungen liegt auf den akustischen Verarbeitungsverfahren. Die linguistischen Aspekte der Verarbeitung gesprochener Sprache werden in einem eigenen Teilmodul behandelt.
Ein eingehendes Verständnis von Spracherkennung und Sprachsynthese ist nicht möglich ohne Kenntnisse der Sprachsignalverarbeitung. Hierzu dient im Fach Kommunikationsforschung und Phonetik die Vorlesung Grundlagen der Sprachsignalverarbeitung. Sie beschäftigt sich mit der Darstellung von Sprachsignalen im Rechner sowie mit elementaren Methoden der Analyse von Sprachsignalen. Im Mittelpunkt steht dabei die Kurzzeit-Spektralanalyse bis hin zum Spektrogramm.
Eine der traditionellen Eingangshürden bei der Beschäftigung mit gesprochener Sprache ist
die hierzu benötigte Mathematik. Diese ist sicher nicht schwieriger als die Schulmathematik in
der 13. Jahrgangsstufe, umfasst aber Gebiete, die üblicherweise an den Schulen nicht oder nur
teilweise gelehrt werden. Das zu entwickelnde Modul trägt diesem Umstand Rechnung und versucht dabei auch, den Studierenden die Angst vor der Mathematik zu nehmen, die insbesondere
weiblichen Studierenden - nach Ansicht der Verfasser zu Unrecht - und Geisteswissenschaftler(inne)n nachgesagt wird.
Demgegenüber werden Grundkenntnisse in Phonetik und Linguistik vorausgesetzt. Diese
umfassen insbesondere: Deskriptive Phonetik (Lautschrift der IPA mit ihren deskriptiven Kategorien), Beschreibungsschemata für Vokale und Konsonanten; artikulatorische Phonetik bis hin
zur Koartikulation; akustische Phonetik bis hin zum Begriff des Formanten; phonetische Grundterminologie
(Phonembegriff, Minimalpaaranalyse).
Computerlinguistische Aspekte der Verarbeitung gesprochener Sprache
Die verbreitete Fokussierung der computerlinguistischen Lehrmaterialien auf die geschriebene Sprache führt tendenziell zur Ausblendung von Fragestellungen, die für die syntaktische und semantisch-pragmatische Verarbeitung gesprochener Sprache spezifisch sind. Diese Fragen sollen vom Teilmodul Linguistische Aspekte beleuchtet werden; eine enge Vernetzung des Teilmoduls mit den übrigen MiLCA-Modulen sorgt für eine Integration der spezifischen Fragestellungen dieses Teilmoduls in die entsprechenden Kontexte der übrigen Module. Es wird der Übergang von den anderen MiLCA-Modulen zum den jeweils thematisch verwandten Abschnitten des Teilmoduls Linguistische Aspekte gesprochener Sprache möglich sein. Andererseits verweisen Abschnitte dieses Teilmoduls auf andere MiLCA-Module, die zuvor oder gleichzeitig zu erarbeiten sind.
Unter den in diesem Teilmodul behandelten spezifischen Aspekten der linguistischen Verarbeitung gesprochener Sprache sind insbesondere die folgenden zu unterscheiden:
Das Modul gliedert sich in mehrere Teilmodule:
1. Einführung: Übersicht über Aufgaben und Einsatzmöglichkeiten der akustischen Mensch-Maschine-Kommunikation
Diese im wesentlichen deskriptive Übersicht soll in die Thematik einführen und die einzelnen Aufgaben benennen. Sie soll aber auch die Voraussetzungen hinsichtlich der Sprachsignalverarbeitung nennen, die für das Verständnis der Zusammenhänge notwendig sind und in der Einheit Grundlagen der Sprachsignalverarbeitung gelehrt werden.
2. Grundlagen der Sprachsignalverarbeitung
Exkurs: Für die Verarbeitung gesprochener Sprache benötigte Mathematik
Beim Entwurf dieses Moduls wird besonders zu beachten sein, dass die Benutzer(innen) über sehr heterogene Eingangsvoraussetzungen verfügen. Dies gilt insbesondere bezüglich der hier benötigten Mathematikkenntnisse. Diese sollen in einem vom Haupttext abgesetzten Teilmodul aufgearbeitet und von verschiedenen Stellen innerhalb des Gesamtmoduls angesprungen werden können. In jedem Abschnitt - dies gilt insbesondere für das Teilmodul Mathematik - wird eine kleine Kenntnisstandprüfung ("Einstufungsprüfung") vorgeschaltet, auf deren Grundlage den Studierenden mindestens drei alternative Pfade angeboten werden: a) Überspringen des Abschnitts bei guten Kenntnissen; b) zusammenfassende Vermittlung des Inhalts (Kurzpfad); c) detaillierte Vermittlung des Inhalts mit abschließender Überprüfung des Lernfortschritts. Dieser modulare Aufbau erlaubt es, insbesondere Studierende mit Nachholbedarf in Mathematik und solche, die nicht vorurteilsfrei an die Sache herangehen ("Angst vor Mathematik", die insbesondere weiblichen Studierenden gern nachgesagt wird), auf den Kenntnisstand zu bringen, der für das weitere Verständnis notwendig ist.
3. Spracheingabe, Spracherkennung, Sprachverstehenssysteme
Dieses Teilmodul soll den Studierenden einen Überblick über die Entwicklung und den heutigen
Stand der Spracherkennung geben und sie in die Lage versetzen, Probleme der Spracherkennung zu verstehen und
zu beurteilen. Wie im Teilmodul Sprachsynthese werden auch hier an einigen Stellen Kenntnisstandsprüfungen
eingestreut, die sich auf den Stoff aus Grundlagen der Sprachsignalverarbeitung beziehen und ggf. auf das entsprechende
Teilmodul rückverweisen. Der Lernfortschritt wird am Ende jedes Abschnitts überprüft.
Zum Kennenlernen von Betrieb und Anwendung eines Spracherkennungssystems soll ein einfacher,
interaktiver und trainierbarer Spracherkenner mit geringem Wortschatz zur Verfügung stehen, beispielsweise
für die Erkennung der zehn Ziffern oder anderer, durch den Benutzer zu definierender Wörter.
4. Sprachausgabe, Sprachsynthese
Dieses Teilmodul soll den Studierenden einen Überblick über die Entwicklung und den heutigen
Stand der Sprachsynthese geben und sie in die Lage versetzen, die Probleme der Sprachsynthese
zu verstehen und zu beurteilen.
Verschiedene experimentelle und auch kommerziell erhältliche Systeme haben eigene
interaktive Webseiten, auf denen Beispiele synthetisiert und anschließend wiedergegeben werden können.
Hiervon soll ausgiebig Gebrauch gemacht werden, damit sich die Studierenden selbst einen Überblick
darüber verschaffen können. Eigene Demos sollen dann angesteuert werden können
(Einstiegspunkte nicht extra in der Gliederung gekennzeichnet), wenn es notwendig ist, genauer in ein System
"hineinzuschauen" bzw. hineinzuhören. Dies sind insbesondere: parametrische Synthese
(vgl. auch Visualisierung des Vokaltrakts); Manipulation prosodischer Parameter (Dauer, Lautstärke,
Grundfrequenz); Kostenfunktionen und Verkettungsregeln bei der korpusbasierten Synthese.
An einigen Stellen werden Kenntnisstandsprüfungen eingestreut, die sich auf den Stoff aus
Grundlagen der Sprachsignalverarbeitung beziehen und ggf. auf das entsprechende Teilmodul
rückverweisen. Der Lernfortschritt wird am Ende jedes Abschnitts überprüft.
5. Linguistische Aspekte der Verarbeitung gesprochener Sprache
Im Gegensatz zu den Teilmodulen Sprachsynthese und Spracherkennung, die im wesentlichen die speziellen akustischen Probleme und Aufgaben beschreiben, werden hier die Aspekte gesprochener Sprache behandelt, die auf den Symbolebenen (Phonologie, Lexikon, Syntax, Semantik, Pragmatik) relevant sind. Dieses Teilmodul nimmt also eine Brückenfunktion ein zwischen den akustikorientierten Teilmodulen Spracherkennung und Sprachsynthese, die in Bonn bearbeitet werden sollen, und den computerlinguistischen Modulen, die bei anderen Partnern entwickelt werden und sich im wesentlichen mit geschriebener Sprache beschäftigen. Das Teilmodul ist mit den Teilmodulen Spracherkennung und Sprachsynthese eng verzahnt, ohne dass die Links in der Gliederung im einzelnen angegeben werden.
Multimediale Elemente und interaktive Demos:
Im Zentrum der interaktiven Demos steht ein Sprachsignallabor, das folgende Grundfunktionalitäten umfassen soll:
- Akustische Aufnahme und Wiedergabe, Digitalisierung
- Selektion von Teilsignalen, Editieren von Signalen
- Amplitude, Stimmhaftigkeit, Grundfrequenz
- Oszillogramm
- Spektrogramm / Sonagramm
- Einzelspektrum
Weitere Elemente:
· Vokaltraktsimulator zur Visualisierung von Artikulationsgesten (hier beschränkt auf Vokale) mit akustischer Ausgabe;
· ein einfaches Spracherkennungssystem mit geringem, aber trainierbarem Wortschatz;
· Sprachsynthese mit verschiedenen Verfahren (Klatt-Synthesizer, PSOLA etc.)
· eine Möglichkeit zur prosodischen Manipulation natürlicher und synthetischer Sprachsignale
Zur Wahl des Szenarios
Das MiLCA-Modul Gesprochene Sprache ist als WBT-Modul konzipiert, da diese Lernform uns als die geeignetste für die individuelle Ausgestaltung der Lerngeschwindigkeit und der Lernziele erscheint. Die individuelle Ausgestaltung der Lerngeschwindigkeit reagiert auf die erfahrungsgemäß großen Unterschiede der Studierenden hinsichtlich der mathematischen Voraussetzungen für die Grundlagen der Signalverarbeitung und auf die individuellen Unterschiede beim Aufwand, sich diese Kenntnisse zu erarbeiten. Da diese individuellen Unterschiede zu Beginn des Kurses ausgeglichen werden müssen, läuft eine synchrone Taktung der Lerneinheiten eher dem tutoriellen Ziel des Kurses zuwider, da sie zwangsläufig einigen Studierenden in der Anfangsphase zu wenig Zeit lassen oder für andere, mathematisch Fortgeschrittenere die Abfolge von Lerneinheiten in dieser Phase zu sehr strecken würde.
Die individuelle Bestimmung der Lernziele und das Angebot mehrerer Lernpfade durch das Modul legt ebenfalls ein WBT-Konzept nahe. Da das Modul Gesprochene Sprache im Teilmodul Linguistische Aspekte eng mit anderen Modulen verzahnt ist und Studierende der Computerlinguistik sich unter verschiedenen Fragestellungen dem Modul nähern können, soll eine Erarbeitung von Teilen des Moduls in unterschiedlichen zeitlichen und thematischen Kontexten möglich sein. Die hierzu notwendige Flexibilität kann bei einer Bindung des Moduls an eine vorgegebene synchrone Taktung der Lerneinheiten nicht erreicht werden.
Umfang des Moduls
Für den Umfang des Moduls ist ein Äquivalent von 4 Semesterwochenstunden (SWS) vorgesehen. Die einschlägigen Lehrveranstaltungen für Phonetiker und Computerlinguisten an der Universität Bonn umfassen 3 Vorlesungen je 2 SWS, also insgesamt 6 SWS. Der Verfasser sieht kaum eine Möglichkeit, diesen Umfang grundsätzlich zu vermindern, wenn alle Aspekte der Mensch-Maschine-Kommunikation mit gesprochener Sprache berücksichtigt und zusätzlich die Grundlagen der Sprachsignalverarbeitung vermittelt werden sollen. Sofern für das Projekt der Umfang auf ein Äquivalent von 4 SWS gedrückt werden soll, ist die Möglichkeit vorgesehen, die Breite des Moduls zu belassen und bei der Vermittlung der Unterpunkte von Sprachsynthese und Spracherkennung weniger ins Detail zu gehen bzw. die Auswahl der Aspekte zu beschränken. Hierbei soll im Verlauf des Projekts und in Absprache mit den Partnern entschieden werden, welche Punkte im einzelnen betroffen sind.
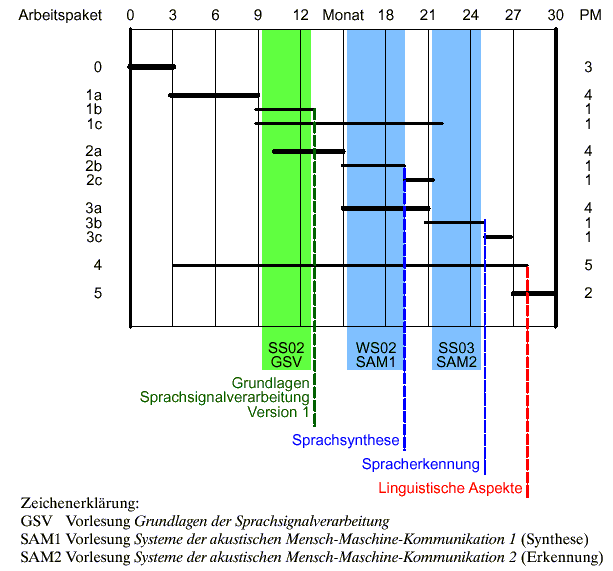
Der Arbeitsplan für die Erstellung des Moduls orientiert sich am Veranstaltungsplan im Fach Kommunikationsforschung und Phonetik an der Universität Bonn, weil damit die Teilmodule im Rahmen dieser Lehrveranstaltungen mit den Studierenden des Fachs getestet werden können und so Synergieeffekte zu erwarten sind. Die Vorlesung Grundlagen der Sprachsignalverarbeitung wird in jährlichem Zyklus im Sommersemester angeboten. Die in viersemestrigem Zyklus gehaltenen Vorlesungen Systeme der akustischen Mensch-Maschine-Kommunikation 1, 2 laufen zum jetzigen Zeitpunkt und werden im akademischen Jahr 2002/03 wieder angeboten. Dementsprechend ergibt sich folgender Arbeitsplan:
| Arbeitspaket 0: | Grundsätzliche Vorbereitung: Erstellung einer detaillierten Gliederung; Fragen der Gestaltung der Benutzeroberfläche, Einbindung der Demonstrationen; Festlegung der grundsätzlichen Struktur des Moduls und der internen Beziehung der Teilmodule, insbesondere die Einbindung des Teilmoduls Mathematik (3 PM) |
| Arbeitspaket 1a: | Erstellung des Teilmoduls Grundlagen der Sprachsignalverarbeitung mit den zugehörigen Abschnitten des Teilmoduls Mathematik (4 PM) |
| Arbeitspaket 1b: | Test des Teilmoduls Grundlagen der Sprachsignalverarbeitung im Rahmen der Lehrveranstaltung im Sommersemester 2002 (1 PM) |
| Arbeitspaket 1c: | Weiterentwicklung des Teilmoduls Grundlagen der Sprachsignalverarbeitung; Entwicklung und Integration der interaktiven multimedialen Elemente ("Sprachsignallabor" sowie weitere interaktive Demos) und Integration des Teilmoduls in das Bonner Modul (2 PM) |
| Arbeitspaket 1d: | Abschließender Test des Teilmoduls im Rahmen der Lehrveranstaltung im Sommersemester 2003 (1 PM) |
| Arbeitspaket 2a: | Entwicklung des Teilmoduls Sprachsynthese (4 PM) |
| Arbeitspaket 2b: | Test des Teilmoduls Sprachsynthese einschließlich der zugehörigen Abschnitte aus dem Teilmodul Linguistische Aspekte (siehe AP 4) im Rahmen der Lehrveranstaltung "Systeme der akustischen Mensch-Maschine-Kommunikation 1" (1 PM) |
| Arbeitspaket 2c: | Weiterentwicklung des Teilmoduls und Integration in das Bonner Gesamtmodul (1 PM) |
| Arbeitspaket 3a: | Entwicklung des Teilmoduls Spracherkennung (4 PM) |
| Arbeitspaket 3b: | Test des Teilmoduls Spracherkennung einschließlich der zugehörigen Abschnitte aus dem Teilmodul Linguistische Aspekte (siehe AP 4) im Rahmen der Lehrveranstaltung "Systeme der akustischen Mensch-Maschine-Kommunikation 2" (1 PM) |
| Arbeitspaket 3c: | Weiterentwicklung des Teilmoduls und Integration in das Bonner Modul (1 PM) |
| Arbeitspaket 4: | Entwicklung des Teilmoduls Linguistische Aspekte, Integration in die Teilmodule Sprachsynthese und Spracherkennung, Test im Rahmen der zugehörigen Lehrveranstaltungen und abschließende Integration in das Bonner Gesamtmodul. Herstellung der Links zu den Modulen der anderen Partner (5 PM) |
| Arbeitspaket 5: | Abschließende Arbeiten zu Gesamtintegration; Abstimmung der Module aufeinander, Integration zum Gesamtsystem (2 PM) |